How Appian Subprocesses’ Design Affects Memory and Performance
Appian Process Models are the “plumbing” that connects all of your workflows into a single unified workflow for highly-effective, streamlined processes. Even though they are invisible to your end-users, they are one of the most critical elements of a successful project. Therefore, the implementation team should put a lot of analysis and planning into performant design to avoid scaling issues and frustrated users.
However, there is not a one-size-fits-all for designing a process model either. In this blog, I will discuss the technical impacts of certain design choices on the performance and available memory of your Appian system.
Use-Case:
A bank has a loan application process that involves Applicants working with Bank Associates. After an Applicant submits a loan request, an Associate can approve the loan. If the Associate wants to approve a loan over a certain pricing threshold, it requires their Manager’s approval before finalization. Once the approval is finalized by the Manager, an email will be sent out to the Applicant alerting them their loan was approved. If the Manager does not approve the application, then it gets sent back to the Associate to make adjustments based on the Manager’s feedback. This is an example involving concurrent users and editor permissions, something many process instances require.
Additionally, the submission form Associates send to their Managers for approval contains a numeric confidence score. This score is generated by the Bank’s internal system to determine how likely the Applicant is to pay off the loan depending on the different custom data types inputted. From a technical perspective, this involves a large and complex query and an array of values. We’ll discuss two different design approaches as shown below to best handle this use-case within a Process Model.
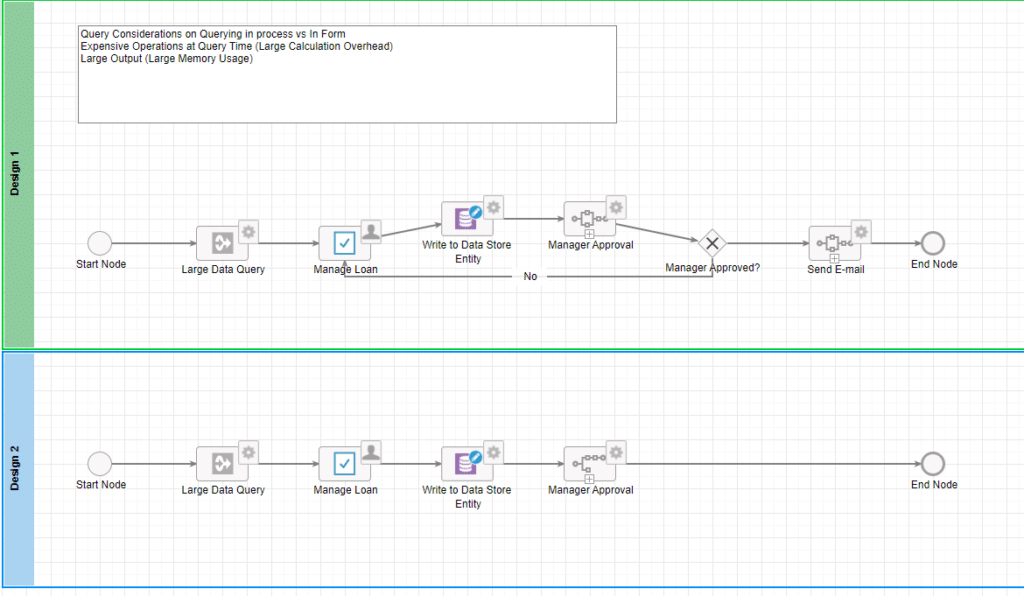
The above picture outlines the process for an Associate to submit an application. In Design #1 the major difference is that the “Manager Approval” sub-process is synchronous. This means this process will not complete until the Manager’s task is completed. In Design #2, the process will complete, because the Manager Approval sub-process is asynchronous. On the surface these processes seem very similar, so what is the pro and con of each design?
Design #1
Pro: “Large Data Query” will only run once in the event the Manger rejects this.
Con: The process is staying in memory
Design #2
Pro: Freeing up memory by allowing the process to complete and archive
Con: “Large Data Query” will run for every rejection
The key considerations for which design to choose comes down to answering these questions:
- How likely is the Manager to reject this application instead of this process being a formality?
- How long does a Manager keep active loan approval tasks in their queue?
The reason these questions are important is that the answer can determine which design is a better fit for your system. For example, if this process is collaborative and Managers typically reject applications multiple times before approval, then Design #2 has a drawback. Using Design #2, each Manager rejection would cause a new process to kick-off and the Large Data query to be run again. This large query that’s running many times can cause performance issues, a worse response time, and a poor user experience. On the other hand, Design #1 wouldn’t kick off a new process if the Manager rejects the loan application.
Additionally, one of the additional details to consider is how long Managers keep approval tasks in their queue. If Managers typically let these tasks sit for long periods of time, like weeks, the amount of active processes will build up in Design #1, since they are synchronous. As a result, the parent processes will not complete or archive. Keeping these parent processes active can affect the available memory consumption within Appian, which also affects system performance. This issue is compounded if the large data query contains a large data set, which will also be sitting in memory unnecessarily, and may lead to a decline from the usual performance expectations.
So what should you do? Is it more important for your system to free up memory or to prevent large queries to the database?
The reason for discussing the benefits and drawbacks of different design choices is because there is no single answer to this question. It’s important to understand and investigate the biggest hits to your own Appian system’s performance if you’d like to improve your users’ experience. When designing process models, the VPS team likes to organize synchronous parent processes in a way that they will not carry an excess amount of data in memory, such as below.
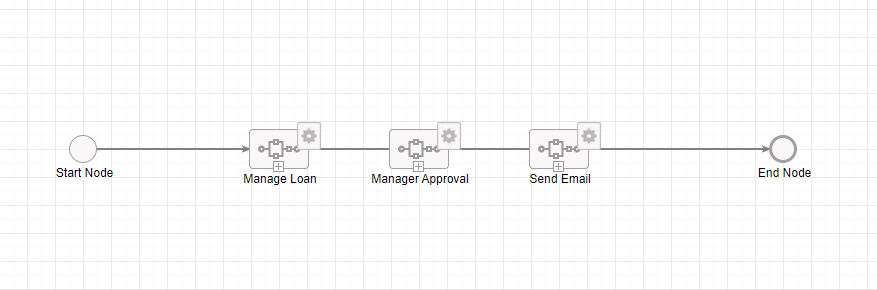
However, this does not mean that we would automatically refactor an existing process model that doesn’t have this design structure. There’s risk associated with design changes, such as dependencies to other processes. Our team would first need to understand the performance benefit of refactoring the process model.
The best thing you can do is let your metrics and data speak for itself. This might seem complicated to know which processes are impacting your system the most. One option to solve this is bringing in a performance testing team. A performance testing team can identify how long it takes for your users to complete a specific process. Performance testing teams monitor metrics that affect system speed–such as load times–against a testing environment that uses a production-like amount of users and data. Based on test results, the performance team recommends changes to the development team.
Performance testing teams are a part of Vision Point Systems’ Appian Cloud services offering for this exact reason. We frequently couple our developers’ experience and a performance testing team’s data-driven approach to build performant and scalable systems. If you’d like to learn more about our Performance Testing team or ways you could maximize your Appian system performance you can schedule a meeting here.
